MSTW PDFs : random predictions from eigenvector PDF setsHere we provide supplementary material associated with the paper: G. Watt and R. S. Thorne,Recall the usual formula in the Hessian approach for symmetric PDF uncertainties of a quantity F calculated using eigenvector PDF sets:  In Section 6 of the above paper it was demonstrated how to generate Npdf random predictions using  where S0 is the best-fit PDF set, n is the number of eigenvectors and Rjk is a random number taken from a Gaussian distribution with mean zero and variance one. Instead of using the best-fit and Hessian uncertainty, an alternative approach to PDF uncertainties is therefore to use the average and standard deviation of Npdf random predictions. Some benefits of this approach are discussed in the above paper. For example (see Section 7), it is possible to perform Bayesian reweighting using the random predictions as for the NNPDF sets. Below we provide some ROOT scripts to assist with the practical implementation and we give some further applications of the random predictions going beyond those discussed in the paper. Update (9th January 2015): The formula above, Eq. (6.5) of the paper, has been found to be flawed as it does not preserve correlations. The necessary correction is to keep the sign of the quantity enclosed by |...| rather than taking the absolute value. This correction should be made in the scripts provided below. The LHAPDF6 implementation has been corrected as of today.
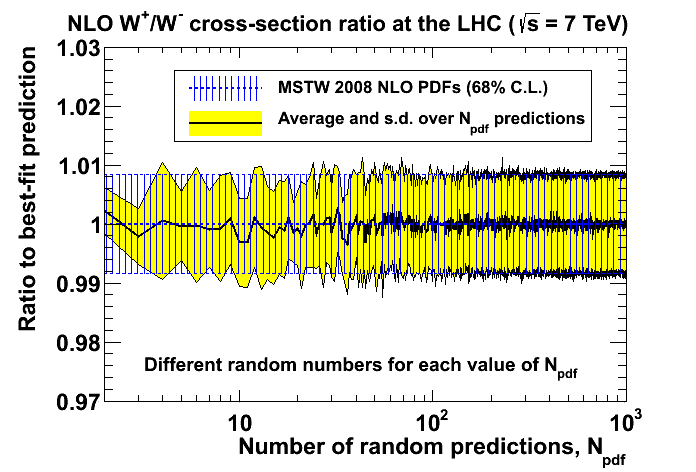
Convergence of random predictions as a function of NpdfThe ROOT script convergence.C reproduces the plots in Figures 13 and 14 of arXiv:1205.4024v2.Figure 13: Convergence of average and standard deviation of Npdf random predictions as a function of Npdf, each time adding one more random prediction to the Npdf − 1 previous random predictions, normalised to the best-fit prediction and compared to the Hessian uncertainty. 



Figure 14: Convergence of average and standard deviation of Npdf random predictions as a function of Npdf, each time generating Npdf independent random predictions with different random numbers, normalised to the best-fit prediction and compared to the Hessian uncertainty. 


Statistical combination of random predictions from different PDF groupsThe ROOT script combination.C demonstrates a statistical combination of random predictions from three different PDF sets as an alternative to the PDF4LHC envelope prescription. The script generates Npdf = 100 random predictions for each of MSTW08 and CT10, then combined with the Nrep = 100 predictions from NNPDF2.1, the statistical combination is given by the average and standard deviation over the total of 300 predictions. The script produces the following plots: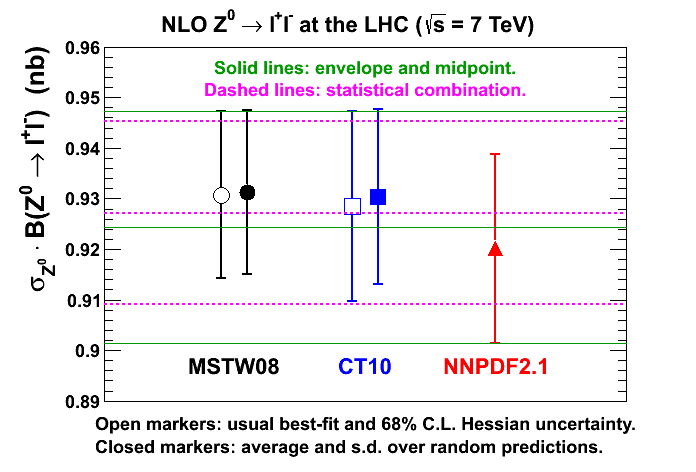



Note that in this simple example it is not strictly necessary to produce the random predictions using the formula above (in terms of n eigenvectors) with n random numbers Rjk associated with each random prediction. If considering only one quantity F in isolation (as done here), then random predictions could be produced directly from the best-fit prediction and Hessian uncertainty of F, i.e.  so that there is only one random number Rk associated with each random prediction. However, if considering more than one quantity F it is necessary to use the formula above (in terms of n eigenvectors) to preserve all the correlations between the fitted PDF parameters. This would be necessary, for example, if calculating the PDF correlation between two cross sections from a combination of three different PDF sets. It is also necessary for the Bayesian reweighting procedure where one wants to examine the impact on the PDFs of including new data; see Section 7 of the paper. See also more recent plots at NNLO here.
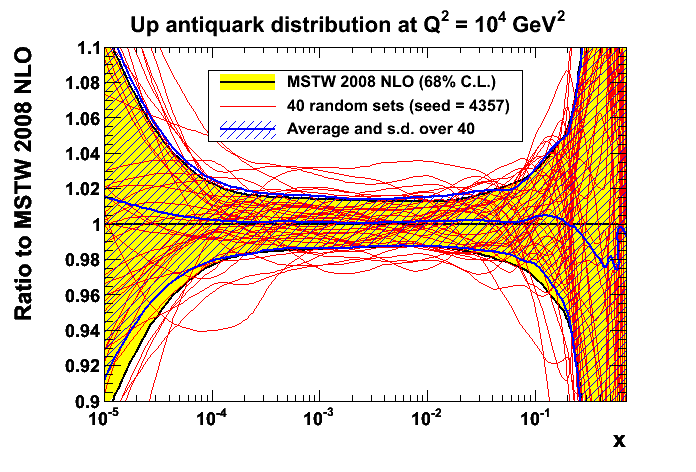
Conversion of MSTW .LHgrid files from Hessian to randomAs discussed in the paper, and as should be clear from the material above, it is unnecessary to directly produce dedicated randomly-distributed PDF sets, for example, in the form of .LHgrid files for use with the LHAPDF interface. It is more efficient to first calculate predictions using the usual best-fit and eigenvector PDF sets from the existing .LHgrid files, then to later generate the random predictions only when needed (“on the fly”), as done in the example scripts above (convergence.C and combination.C). On the other hand, it might still be useful for certain applications to have a .LHgrid file containing random MSTW PDF sets that can be processed in exactly the same way as the NNPDF grid files. Therefore we provide a ROOT script conversion.C that takes as input any of the MSTW .LHgrid files containing the best-fit and 40 eigenvector PDF sets, then produces as output a new .LHgrid file containing 40 random PDF sets (with the zeroth member set given by the average over the 40). The limit of Npdf = 40 is chosen to avoid increasing array sizes in the LHAPDF5 source code, so that no recompilation of LHAPDF5 is required. More random PDF sets (in batches of 40) can be generated simply by running the ROOT script with different random seeds. In principle, similar conversion scripts could also be written for the eigenvector PDF sets provided by other PDF fitting groups. An example of Npdf = 40 random PDF sets produced with the default settings of the conversion.C script (with seed 4357) is shown below, where the average and standard deviation is compared with the best-fit and symmetric Hessian uncertainty.Note that the conversion.C script uses the .LHgrid file format of LHAPDF5 and only works for MSTW PDF sets. A more general conversion program, that works for any PDF set given in the form of a best-fit and Hessian eigenvector PDFs, is provided as examples/hessian2replicas.cc in LHAPDF 6.1.0 (released 25th April 2014). 




Comments to Graeme.Watt(at)durham.ac.uk. |